

Kiedy ChatGPT był jedynie ciekawostką ze świata nowych technologii, a nikt z nas nie zastanawiał się jeszcze, czy zdjęcie, na które właśnie patrzymy, zostało stworzone przez człowieka, czy algorytm, trudno było spodziewać się, że w ciągu kilku lat AI zadomowi się niemal w każdej dziedzinie życia. Sztuczna inteligencja to dziś nie tylko systemy wykorzystywane w medycynie, przemyśle lub wojskowości – to również generowane na co dzień pomysły na obiad, zabawne przeróbki zdjęć w social mediach, spersonalizowane odpowiedzi na zapytania w internecie czy zautomatyzowane zarządzanie zaplanowanymi spotkaniami.
Z roku na rok zwiększa się nie tylko zakres możliwych zastosowań AI, ale również liczba dostępnych narzędzi, wśród których, choć prym wciąż wiodą propozycje największych światowych koncernów, można znaleźć także modele opracowane w Polsce – mowa o Bieliku i PLLuM.
Polska odpowiedź na ChatGPT, czyli Bielik
Chociaż obszary, w jakich AI jest wykorzystywana, są niezwykle różnorodne i wciąż się poszerzają, większość z nas na co dzień ma do czynienia przede wszystkim z dużymi modelami językowymi (ang. large language models, LLM). Pozwalają one głównie na generowanie tekstów, a także na wykonywanie rozmaitych operacji na nich – część z nas korzysta z nich więc np. w pracy w branży content marketingu, inni natomiast używają ich choćby do znajdowania odpowiedzi na pytania, inspiracji dla własnej twórczości, tworzenia harmonogramów czy streszczania dłuższych artykułów.
Duży model językowy (ang. large language model) – model sztucznej inteligencji umożliwiający generowanie i przetwarzanie tekstu, wykorzystujący mechanizm uczenia maszynowego.
Każdy polski użytkownik, który miał styczność z LLM, choćby w najpopularniejszych formach jak ChatGPT albo Google Gemini, wie jednak, że mimo swojej wszechstronności miewają one problemy z radzeniem sobie z naszym językiem oraz rozumieniem kontekstów kulturowych zrozumiałych jedynie w Polsce. Stopień skomplikowania językowego, a także niuanse znane wyłącznie Polakom bywają błędnie interpretowane przez AI. Odpowiedzią na te problemy ma być Bielik – model opracowywany w języku polskim od podstaw.
Najpotężniejsze superkomputery w służbie polskiego AI
Bielik jest modelem językowym opartym na francuskiej architekturze Mistral-7B typu open-source, rozbudowanej jednak w znacznym stopniu, tak aby jego podstawę stanowiły organiczne, polskojęzyczne teksty, a nie anglojęzyczne, jak w zdecydowanej większości ma to miejsce choćby w przypadku ChatuGPT. Ten ostatni, podobnie jak wiele innych zagranicznych LLM, miewa bowiem problemy z bardziej skomplikowanymi treściami w języku polskim, np. prawniczymi albo naukowymi, podobnie jak z idiomami czy nawiązaniami literackimi.
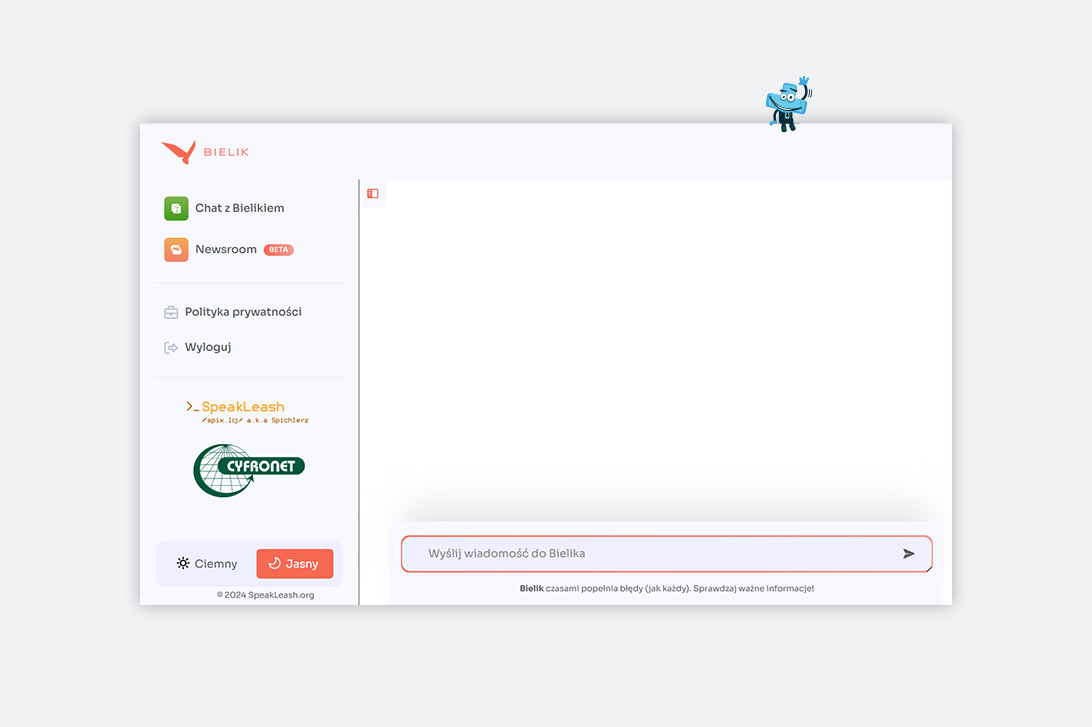
Stworzenie i uruchomienie Bielika jest wynikiem współpracy Akademickiego Centrum Komputerowego Cyfronet Akademii Górniczo-Hutniczej w Krakowie oraz Fundacji SpeakLeash. W tym celu pierwsze z nich udostępniło moc obliczeniową 2 najszybszych polskich superkomputerów – Heliosa i Atheny – natomiast druga wykorzystała największą w Polsce bazę danych w języku polskim, ściśle kontrolowanych pod względem poprawności, merytoryki oraz różnorodności. Dzięki temu Bielik dysponuje 11 miliardami parametrów i świetnie radzi sobie z pracą nad polskojęzycznymi treściami.
Oparcie Bielika na zróżnicowanych tekstach napisanych w języku polskim w założeniu ma pozwolić nie tylko na tworzenie treści poprawnych językowo, trafnie interpretujących konteksty kulturowe, związki frazeologiczne, kolokwializmy czy metafory charakterystyczne dla naszego kraju. Taki wyspecjalizowany model językowy ma skuteczniej radzić sobie również z pracą nad trudniejszymi lub dłuższymi materiałami, na przykład biznesowymi, medycznymi, prawniczymi albo naukowymi. W ten sposób Bielik może stać się przydatnym narzędziem zarówno dla zwykłych użytkowników, jak i dla instytucji państwowych, placówek edukacyjnych, badawczych bądź przedsiębiorstw.
Co więcej, dalsze rozwijanie Bielika może pozytywnie wpłynąć na pozycję Polski na międzynarodowym rynku sztucznej inteligencji, a ponadto zapewnić bezpieczeństwo technologiczne. Opieranie się na systemach opracowanych i zarządzanych przez zagraniczne koncerny niesie bowiem ze sobą ryzyko ograniczenia dostępności do nich – choćby ze względów finansowych, prawnych bądź politycznych. Rozwiązania takie jak Bielik dają zatem ochronę przed takimi sytuacjami, kluczową zwłaszcza dla takich newralgicznych sektorów jak bankowość, ochrona zdrowia czy administracja skarbowa, w których AI już teraz jest stopniowo wdrażana.
Sztuczna inteligencja pod nadzorem rządowym – PLLuM
Stworzenie modelu Bielik może w najbliższych latach okazać się niezwykle istotnym krokiem w procesie cyfryzacji różnorodnych sektorów gospodarki oraz usług publicznych. Jest to jednak inicjatywa oddolna, istniejąca obok innego projektu z obszaru sztucznej inteligencji. Mowa o PLLuM – Polish Large Language Model, który nie stanowi pojedynczego modelu, lecz całą ich rodzinę, opracowywaną z myślą o różnorodnych zastosowaniach AI, w tym w administracji publicznej czy biznesie, ale również do użytku prywatnego. PLLuM oddaje zatem do dyspozycji systemy o różnej skali: mniejsze, do prostszych zadań, a także bardziej zaawansowane, obsługujące nawet do 70 miliardów parametrów. Wszystkie jednak odróżniają się od Gemini, ChatuGPT lub innych popularnych na świecie modeli znacznie lepszym rozumieniem komunikatów w języku polskim.
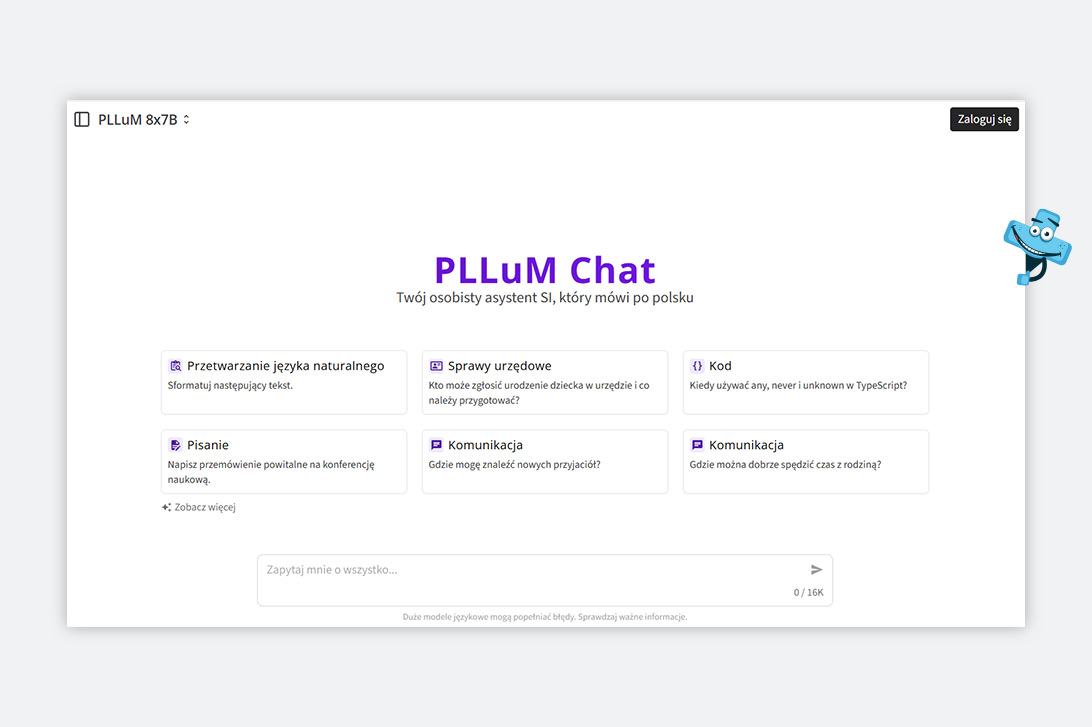
Rozwój i działanie PLLuM znajdują się pod kontrolą Ministerstwa Cyfryzacji, które zleciło jego realizację konsorcjum składającemu się z pracowników:
- Politechniki Wrocławskiej,
- Uniwersytetu Łódzkiego,
- Instytutu Podstaw Informatyki PAN,
- Instytutu Slawistyki PAN,
- Naukowej i Akademickiej Sieci Komputerowej,
- Ośrodka Przetwarzania Informacji.
Modele tworzące rodzinę PLLuM zostały więc opracowane przez ekspertów z różnorodnych dziedzin nauki i wykorzystują licencjonowane zasoby od podmiotów, które udostępniły je do tego celu, podobnie jak materiały prawnie dopuszczone do rozwijania AI. Wśród nich można więc znaleźć np. artykuły specjalistyczne, dokumentację urzędową oraz teksty literackie.
AI do wsparcia administracji publicznej i obywateli
Czat funkcjonujący w ramach rodziny PLLuM, powszechnie dostępny dla każdego użytkownika, został uruchomiony 24 lutego 2025 roku i można z niego korzystać na podobnych zasadach co w przypadku Bielika, ChatuGPT lub Google Gemini. W założeniu modele językowe PLLuM mają mieć jednak znacznie szersze, ważniejsze zastosowania. Jeszcze w tym roku ma bowiem zostać uruchomiony np. wirtualny asystent oparty na AI, działający w aplikacji mObywatel, mający ułatwiać obywatelom Polski znajdowanie rzetelnych informacji publicznych. W najbliższej przyszłości planuje się również stosowanie PLLuM w edukacji, do większej cyfryzacji szkół i uatrakcyjnienia zajęć, a także do automatyzacji obiegu dokumentów urzędowych.
Właśnie z tego powodu rozwijanie rodzimych modeli językowych zamiast polegania na zagranicznych systemach ma ogromne znaczenie dla bezpieczeństwa wprowadzanych i przetwarzanych danych, które nie będą trafiać na serwery prywatnych firm działających w innych krajach. Minimalizuje to ryzyko wycieku informacji kluczowych zarówno dla cyberbezpieczeństwa obywateli, jak i infrastruktury państwowej.
Czy warto zamienić ChatGPT na Bielika albo PLLuM?
Stworzenie, rozwijanie i użytkowanie polskich modeli AI, czy to Bielika, czy PLLuM, w założeniu może więc usytuować Polskę wśród najważniejszych państw kreujących trendy w branży AI, zwiększyć niezależność oraz bezpieczeństwo technologiczne naszego kraju, a także ułatwić życie każdemu z nas na co dzień. Niejedna osoba może jednak zadawać sobie pytanie – czy warto zmienić używany od dawna, sprawdzony ChatGPT na rodzimą alternatywę?
Aby odpowiedzieć sobie na to pytanie, trzeba pamiętać przede wszystkim, że OpenAI, twórcy ChatuGPT, rozbudowują swoje narzędzie znacznie dłużej, niż ma to miejsce w przypadku Bielika bądź PLLuM, korzystając z dużo większej liczby zasobów. Jednocześnie jednak pochodzenie tych ostatnich bywa źródłem kontrowersji natury prawnej, podczas gdy materiały wykorzystywane do trenowania polskich modeli są bardzo dokładnie selekcjonowane i legalne.
Rodzime modele językowe w założeniu mają też zapewniać większe bezpieczeństwo danych, oparte na lokalnej infrastrukturze oraz polskiej legislacji, a ich stosowanie np. w biznesie wkrótce może okazać się bardziej opłacalne niż korzystanie z oprogramowania zagranicznych koncernów. Przykładowo najnowsze, małe modele Bielika 3.0, ogłoszone na majowej konferencji GOSIM AI Paris, są wyposażone w dedykowany tokenizer w języku polskim, optymalizujący wykorzystanie polskojęzycznych jednostek tekstu, a przy tym gotowe do używania jako zautomatyzowani agenci AI.
Trudno oczekiwać, by polskie modele językowe osiągnęły popularność, jaką cieszą się znane na całym świecie AI jak Gemini, ChatGPT czy Perplexity. Wzrost powszechności sztucznej inteligencji będzie jednak pociągał za sobą rosnącą potrzebę rozwiązań dedykowanych do konkretnych zastosowań, sprawdzających się w określonym kontekście kulturowo-językowym, opartych na bezpiecznej, odpowiednio zarządzanej, transparentnej infrastrukturze. Zarówno PLLuM, jak i Bielik mogą wkrótce stać się odpowiedzią na takie wymagania, zapewniając rezultaty lepiej dopasowane do wymagań polskich użytkowników – prywatnych osób, przedsiębiorców oraz instytucji państwowych.